2. Attribute : shape, dtype, device
앞서 만들어진 텐서가 어떤 모양인지, 어떤 데이터 타입인지, 어떤 디바이스(cpu, gpu)로 연결되었는지 확인할 수 있는 명령어들을 배우고자 한다.
1) Tensor.shape
ex) b = torch.ones([3,4,5,5])
b.shape
{[(5,5) 메트릭스] x 4개} 3개
2) Tensor.dtype

텐서 안에는 무조건 같은 데이터타입 사용하기.
ex) a.dtype
==> 결과
torch.int64
# pytorch 자료형 참고
- float_tensor = torch.ones([3, 5, 5], dtype=torch.float) #dype을 float으로 하겠다고 미리 선언
- double_tensor = torch.ones(1, dtype=torch.double)
- complex_float_tensor = torch.ones(1, dtype=torch.complex64)
- complex_double_tensor = torch.ones(1, dtype=torch.complex128)
- int_tensor = torch.ones(1, dtype=torch.int)
- long_tensor = torch.ones(1, dtype=torch.long)
- uint_tensor = torch.ones(1, dtype=torch.uint8)
- bool_tensor = torch.ones(1, dtype=torch.bool)
- float_tensor.dtype
3) Tensor.device

딥러닝은 오래걸리고 복잡하기 때문에 gpu가 필수적이다
cuda : nvdia 에서 만든 낮은 레벨의 하드웨어 컨트롤 프레임워크 -> 파이토치가 이걸 이용해서 gpu 사용
# 현재 해당 tensor가 어느 device에 있는지 확인하는 방법
a = torch.tensor([1,2,3,4,5])
a.device
# 지금 GPU를 사용할 수 있는 환경인지를 확인
torch.cuda.is_available()
# GPU 이름 체크(cuda:0에 연결된 그래픽 카드 기준)
torch.cuda.get_device_name(device=0)
# 사용 가능 GPU 개수 체크
torch.cuda.device_count()
# 텐서를 gpu에 할당하는 두가지 방법
a = torch.tensor([1., 2., 3., 4., 5.]).cuda()
b = torch.tensor([1., 2., 3., 4., 5.]).to("cuda")
b.device
3. Tensor Aggregation : element-wise 연산, min, max, mean
텐서를 축약하는 방법들을 보고자 한다.
1) element-wise 연산
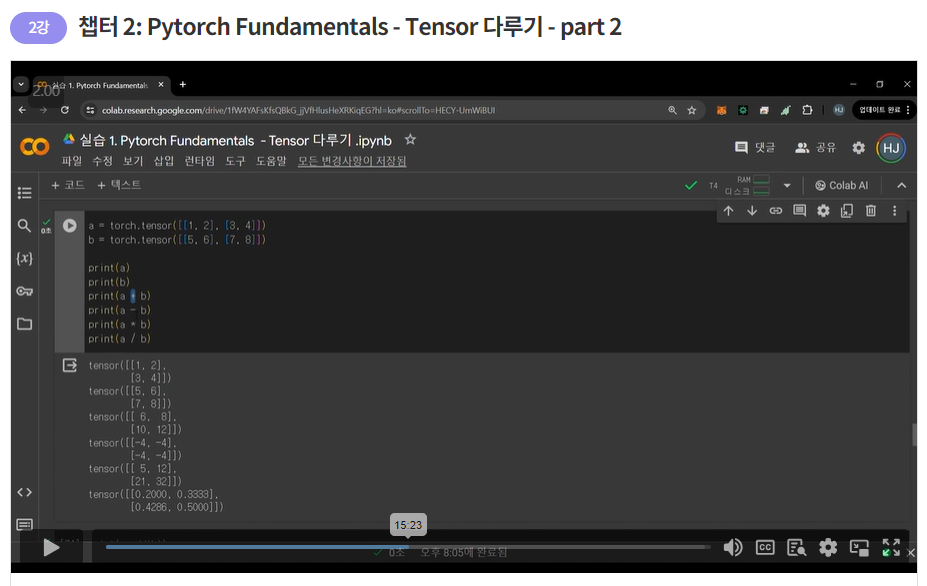
텐서의 같은 자리 원소들끼리 산술 연산
2) inplace 연산
함수 뒤에 _ 를 붙이면 자기 자신의 값을 바꾸게 된다.
연산 결과를 반환하면서 동시에 자기 자신의 데이터를 고침
==> 결과 비교
tensor([[11, 14],
[17, 20]])
tensor([[ 6, 8],
[10, 12]])
tensor([[11, 14],
[17, 20]])
tensor([[11, 14],
[17, 20]])
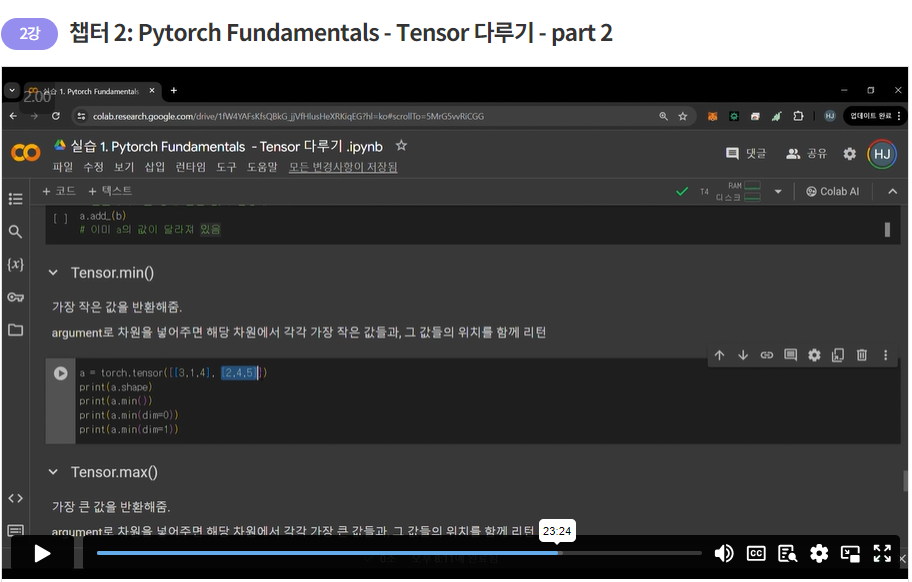
가장 작은 값, 큰 값을 반환해줌.
argument로 차원을 넣어주면 해당 차원에서 각각 가장 작은 값들과, 그 값들의 위치를 함께 리턴
==> 결과
tensor([[3, 1, 4],[2, 4, 5]])
torch.Size([2, 3])
tensor(1)
torch.return_types.min( values=tensor([2, 1, 4]), indices=tensor([1, 0, 0]))
torch.return_types.min( values=tensor([1, 2]), indices=tensor([1, 0]))
4) Tensor.mean()

텐서 전체 평균 혹은 차원별 평균값 리턴
tensor([[1., 2., 3.], [4., 5., 6.]])
tensor(3.5000)
tensor([2.5000, 3.5000, 4.5000])
tensor([2., 5.])
본 게시물은 메타코드 4기 서포터즈 활동의 일환으로 작성한 게시글입니다.




